About MiMoTextBase
Imagine you wanted a ranking of the most common themes in all epistolary novels in French Enlightenment novels, an overview of authors covering “sentimentalism” or a map of all narrative places. The MiMoText knowledge graph combines the linked open data (LOD) paradigm with the infrastructure of a wikibase and text mining methods of data-based literary history. Using the query language SPARQL, users can query this large and growing knowledge graph about the French Enlightenment novel.
MiMoTextBase was built as part of the project “Mining and Modeling Text” (2019-2023). The knowledge graph on about around 2000 French Enlightenment novels stores and provides data via a SPARQL endpoint. It is implemented using a Wikibase infrastructure and integrates various data from heterogeneous sources. Note that the project is ongoing and the contents and structure of the MiMoTextBase will continually be further developed. The purpose of this website, and especially of our tutorial, is to introduce interested students and scholars to our knowledge graph, to convey the potentials of a data-based literary history in combination with linked open data, and to promote new perspectives on the domain, the French Enlightenment novel (1750-1800). In principle, we consider our approach transferable to other humanities disciplines and domains.
The aim of the MiMoText project is to establish a knowledge graph for the humanities built up from various sources and available as linked open data. This means that it is not only freely available and can be linked to other knowledge resources of the Semantic Web, but that it also offers innovative ways to access to scientific information. The following overview, together with our tutorial, is meant to familiarize users with the basics of SPARQL in order to make use of the knowledge graph.
The idea of the Semantic Web was first put forward in 2009 by Tim Berners-Lee, one of the founders of the world wide web (Berners-Lee 2009). Instead of documents, the Semantic Web was to link entities (like names of people, places, things or ideas, etc.), enabling a new way of search and organization of knowledge in the world wide web. In the context of the Semantic Web, the Resource Description Framework (RDF) has established itself as a standard method for formulating simple statements following the structure ‘subject-predicate-object’. These statements are known as RDF triples (Hitzler et al. 2009; Dengel 2012). Each triple consists of two nodes (‘subject’ or ‘object’) and an edge connecting the nodes (‘predicate’ or ‘relation’). Some examples of triples ([Voltaire] -> [author_of] -> [Candide]; [Candide] -> [is_about] -> [philosophy]) are illustrated in figure 1.
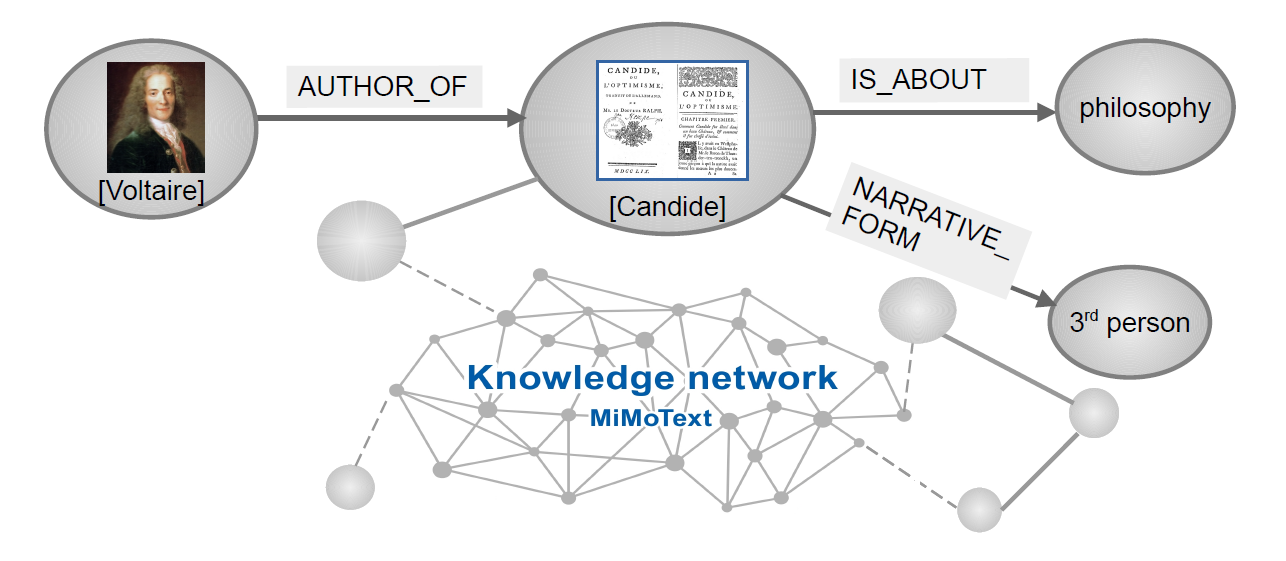
Fig. 1: RDF triples as elements of the MiMoText knowledge graph
One of the biggest hubs for linked open data worldwide at the moment is Wikidata , which was started in 2012 by the Wikimedia Foundation. Wikidata is an attempt to centralize and to structure human knowledge available in the online encyclopedia Wikipedia in a datafied form as RDF triples. With about 8 million SPARQL queries being run every day (Pintscher and Alipio 2021), Wikidata is an open, free and collaborative knowledge base that is readable by humans and machines. All content is published under a Creative Commons Zero License.
The software behind Wikidata is Wikibase, a set of MediaWiki extensions developed by Wikimedia Germany. Just like Wikidata, Wikibase is free and open for everyone. It is used for example by the project ArtBase, the project Enslaved.org or the German National Library. We chose a local instance of Wikibase as the infrastructure for our data in “Mining and Modeling Text” for several reasons:
- Wikibase is suitable for storing the necessary amount of triples and comes with a SPARQL endpoint with numerous visualization possibilities.
- The software is open and free and as with the whole Wikimedia universe, there is a lively community always eager to help and a multitude of communication channels (Wiki conferences, Telegram group, Wikis).
- Wikibase enables us to store a multilingual knowledge graph (French/German/English), which was a feature we intended to use.
- As we match a part of our graph to Wikidata and intend to export a part of our graph to Wikidata too, the use of the same infrastructure as well as the reuse of existing properties was thought to facilitate data integration later.
- We see MiMoTextBase as part of the Wikibase ecosystem. Accordingly, we hope to make interesting data available to other projects and, conversely, to repurpose data made available elsewhere. The more projects in this ecosystem share the same infrastructure, the denser and more significant the whole graph becomes.
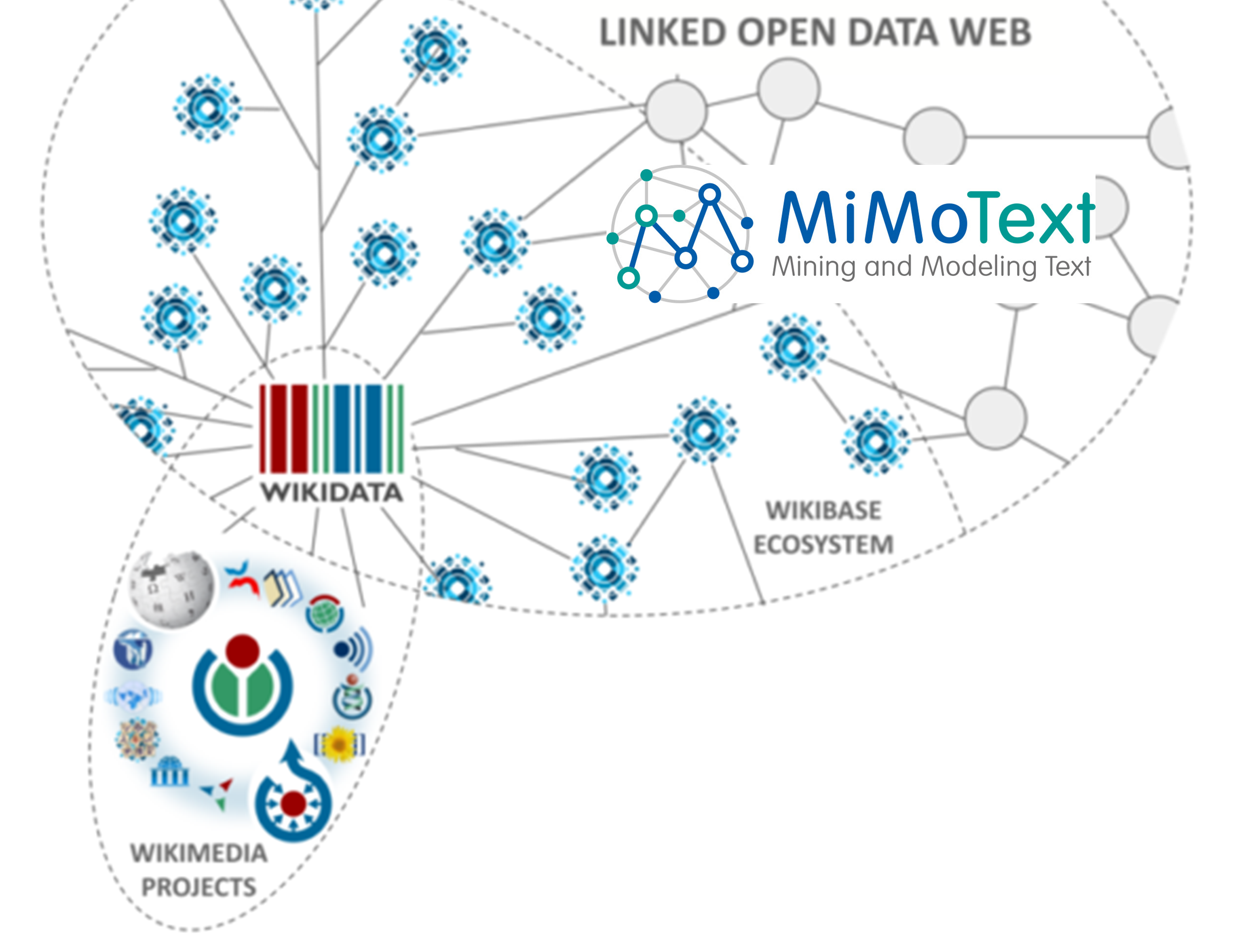
A view of the MiMoTextBase within the Wikimedia Linked Open Data web. Credit original visualization: Dan Shick (WMDE) / CC-BY-SA 4.0.
MiMoText stands for "Mining and Modeling Text: Interdisciplinary applications, informational development, legal perspectives". It is an interdisciplinary project in computational literary studies conducted at the Trier Center for Digital Humanities (TCDH) at the University of Trier. The project is funded by the Research Initiative (2019–2023) of the federal state of Rhineland-Palatinate (Forschungsinitiative Rheinland-Pfalz).
We are dealing with new ways to model and analyze literary history and literary historiography. The overall aim is to establish a knowledge graph that aggregates statements relevant to literary history extracted from various sources. Our application domain is the French novel of the second half of the 18th century – the transfer to other domains and disciplines (other philologies, but also, for example, Philosophy, History and Art) has been planned and conceived from the beginning.
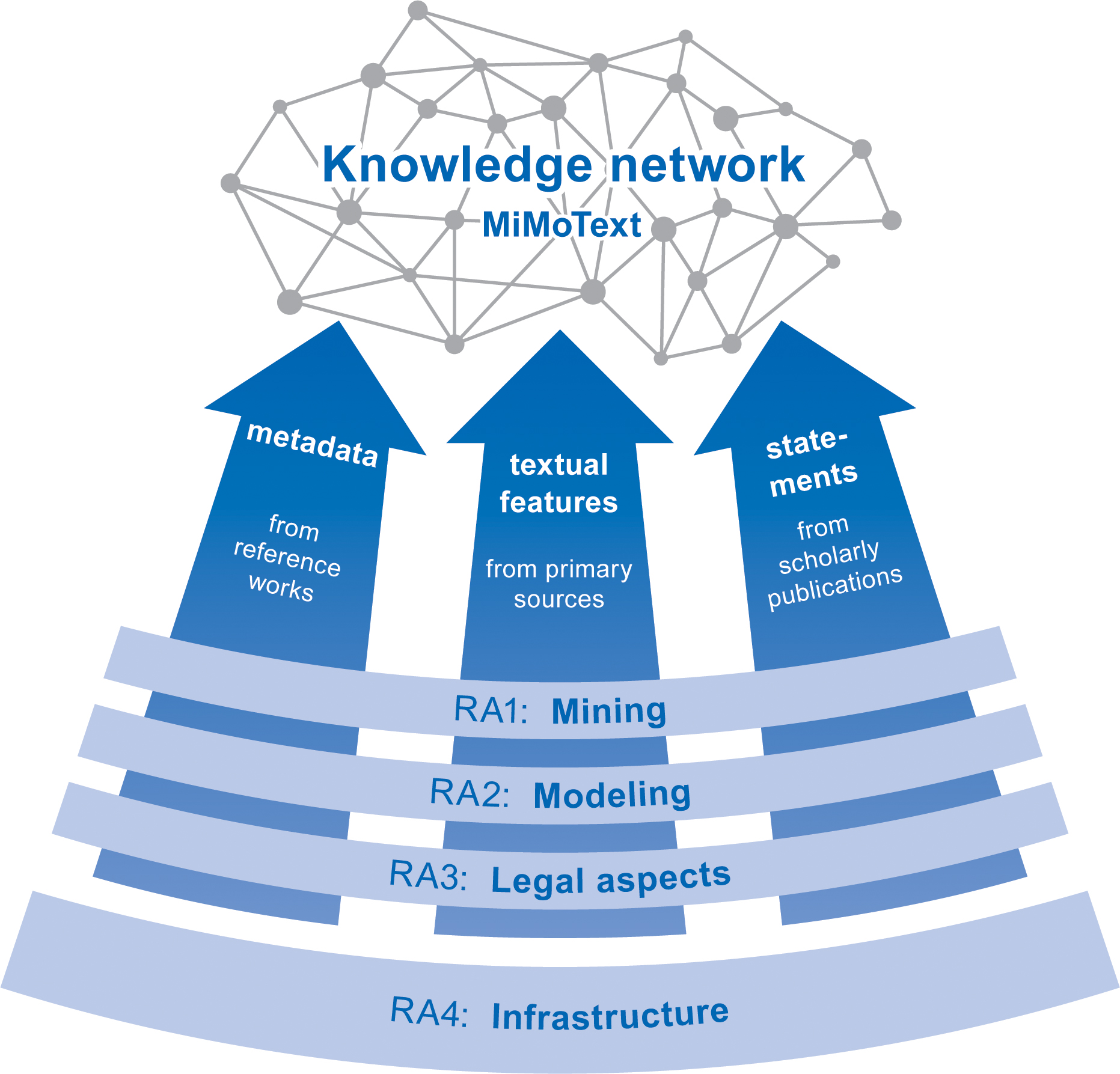
Figure 1: Overview of the project structure with four research areas (RA 1–4) on mining, modeling, legal aspects and infrastructure
On the basis of the three different types of information sources shown in figure 1, methods of text mining and data modeling are intertwined and used to combine several kinds of information: bibliographic metadata from reference works, text features derived from primary texts, and information extracted from scholarly publications. This approach significantly expands the research horizon, because although digitization activities at libraries and archives are now increasing the amount of texts and data available digitally, it is far from possible to capture them systematically through individual human reading. We integrate heterogeneous data into the knowledge graph, link it with other resources in the Linked Open Data universe and enable innovative research on the French Enlightenment novel that can take into account significantly more data than was previously the case. The general vision of “Mining and Modeling Text” is to take steps toward a history and historiography of literature based on data and is inspired by researchers such as Franco Moretti, Matthew Jockers, Katherine Bode or Ted Underwood. For a more detailed description of the project, see our paper Smart Modelling for Literary History (2022).
We construct our knowledge graph from three different types of sources (see fig. 1): bibliographic metadata, primary sources (novels) and scholarly publications.
- Bibliographic metadata: For our domain, the Bibliographie du genre romanesque français 1751-1800 (BGRF, Mylne et al. 1977) is central, as it defines the population of about 2000 French Enlightenment novels. The BGRF has been extensively analyzed and modeled (Lüschow 2020) and contains rich metadata (including places of publication, narrative locations, narrative form, characters, themes, style).
- Novels: In MiMoText, the Collection of Eighteenth-Century French Novels (Röttgermann 2021) is being created. This corpus already includes about 180 novels, which are available as full texts (modeled according to the TEI standard). A subset is available as an extension of the European Literary Text Collection (ELTeC). The results of various quantitative analysis methods applied to primary works serve as the basis for new statements as well. So far, we have applied topic modeling (Schöch et al. 2022; Röttgermann et al. 2022), text mining of places (Hinzmann et al. 2022) as well as text matching. Further planned mining methods include sentiment analysis and keyword analysis.
- Scholarly publications: We examine scholarly literature and annotate statements about literary works and authors of our domain. We have already systematically and quite extensively annotated thematic statements and exploratively annotated other statement types. Currently, we are working on a pipeline that will feed statements annotated in INCEpTION into our Wikibase. Based on this, future work concerns extracting statements automatically and adding statements from scholarly publications to the Wikibase instance.
Some aspects of the Wikibase data model and our modeling approach
We have already outlined above that in the Linked Open Data paradigm, every statement is mapped onto the structure of RDF triples. The Wikibase infrastructure brings with it some special features that affect the data modeling: In Wikibase, 'items' are central. Items can be in subject or object position. Subjects are always 'items', whereas objects can be 'items' or 'values'. The relation or edge that links subject and object is called ‘property’.
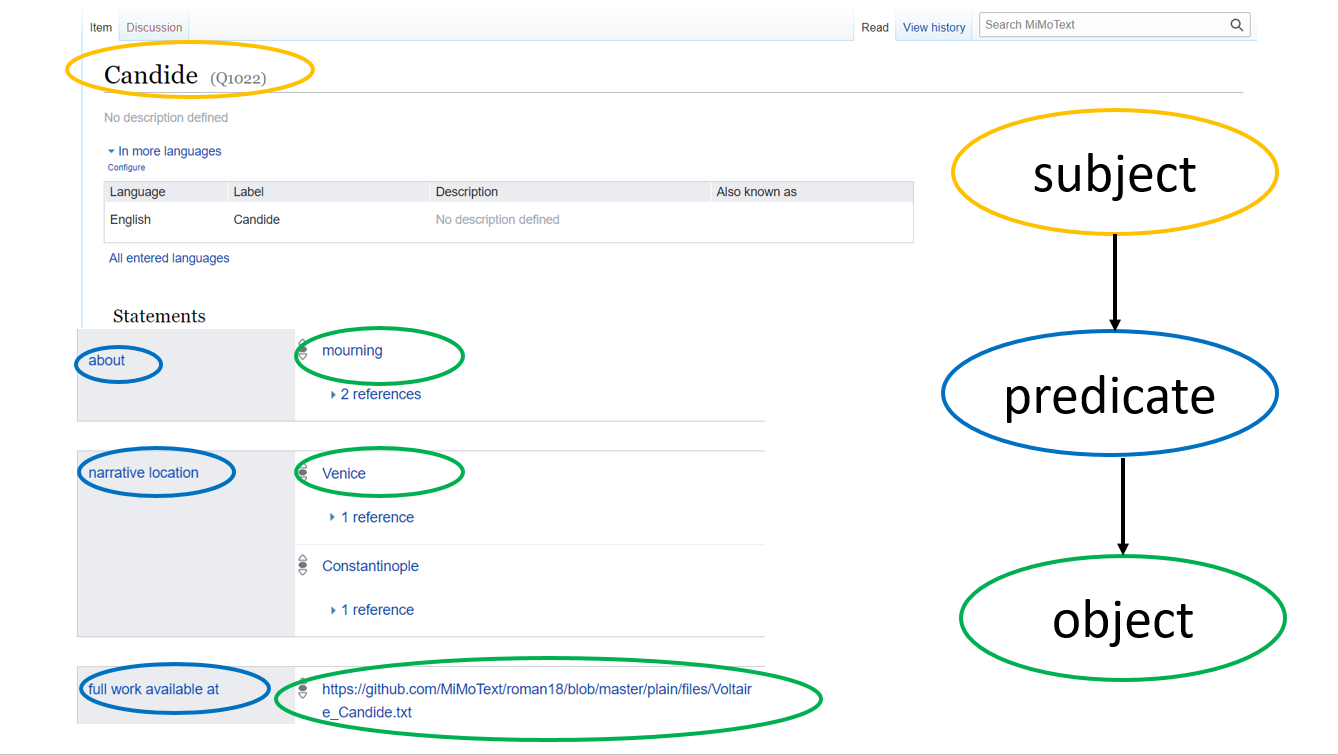
In general, 'statements' in RDF are synonymous with triples (i.e. subject, predicate, object), but in Wikibase the term 'statement' has a slightly different meaning. Statement means not just a triple, but a bundle of multiple triples that refer to a core triple, which is called claim. For an overview of the Wikidata & Wikibase terminology, take a look at the visual comments on item Q42 (Douglas Adams). The ‘core triple’ or ‘claim’ in Wikibase can be ‘referenced’, ‘qualified’ and ‘ranked’, a feature that is very useful in terms of transparency, comprehensibility and comparability.
{kind=link}
The concept of such a bundle of triples constituting a Wikibase statement is based on the fact that statements in the RDF can themselves become the subject of other triples, creating 'statements about statements'. The technical term for this is ‘reification’.
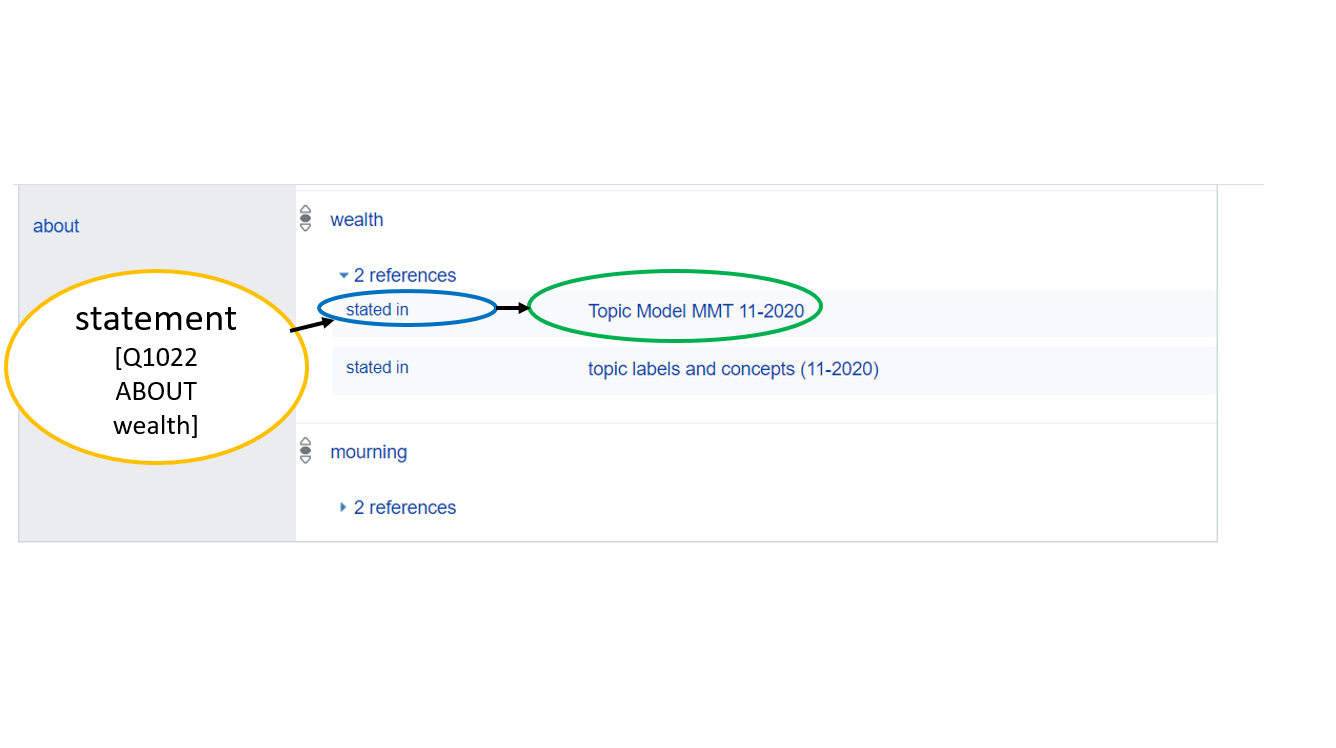
Within our MiMoText graph, the possibility of referencing is
particularly important. Every triple imported into the graph is
referenced by the corresponding source via the property
stated in (P18).
According to our three source types, the references can be a bibliographic work (Q1 in our case) or, alternatively, specific runs of certain analytical methods performed on the novels, e.g. Topic Modeling (Q21) for Named Entity Recognition (Q27). In the future, scholarly publications will also be used as references for triples.
If users are interested in comparing the different sources (Q21 for Topic Modeling / Q1 for Bibliographie du genre romanesque français / Q27 for NER_novels locations) of RDF triples within the graph, they can query those triples only referenced by one specific source or alternatively get to see statements respectively ‘core triples’ referenced by two sources at the same time.
Considering the diversity of sources, there are consistent and concurring statements integrated in the graph. Some statements differ in granularity regarding the entities: For example, we often find larger spatial concepts (continents) in the bibliography, but rather smaller ones (cities etc.) as results of Named Entity Recognition. In addition, by using 'federated queries', information in other knowledge bases can be reused to buffer the heterogeneity and create comparability.
By diversifying our sources (bibliographic metadata, primary sources, scholarly publications), we hope to build a knowledge graph worthy of investigation and exploration. As a side effect, one can explore different outcomes of computational methods and human inquiry in epistemic processes. Generally speaking, the Linked Open Data paradigm and the Wikibase infrastructure offer the possibility to represent the plurality of perspectives and heterogeneous sources that are typical within the humanities. Moreover, uncertain information can also be taken into account, as the reliability level of the 'core triple' can be qualified or ranked.
Modeling decisions briefly outlined
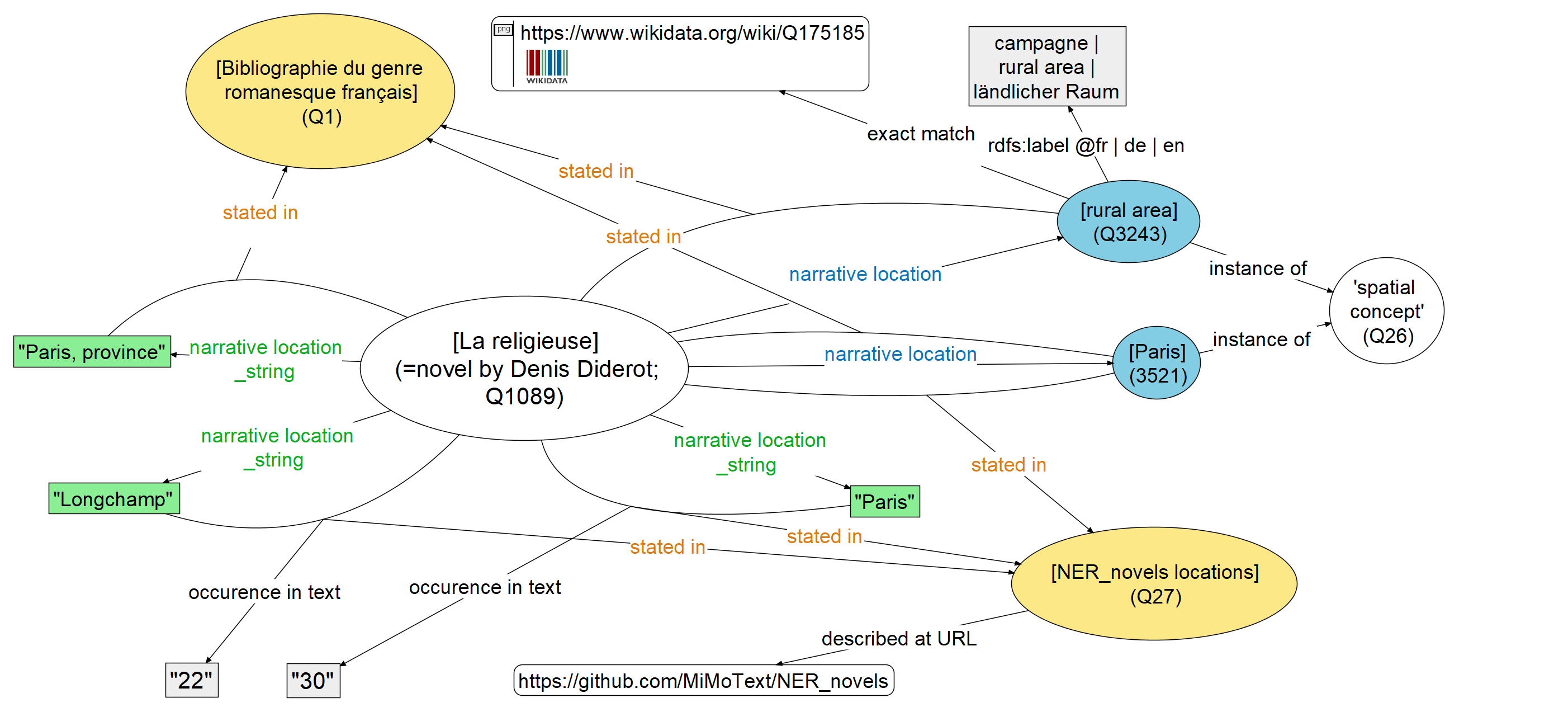
- As already outlined, we reference via the property "stated in" (orange), whereby statements can also be referenced by more than one source. For example, the statement that 'Paris' is a place of action in 'La religieuse' is referenced here by two sources (BGRF = Bibliographie du genre romanesque français and the NER, i.e. Named Entity Recognition related to locations).
- Our approach relies on importing both the text strings as found in the information source (green) and the abstract spatial items (blue) into the MiMoTextBase. Combined with the fact that we reference all statements, this ensures a high degree of verifiability of our data. For example, it can be traced that the statement that 'rural area' can also be considered a narrative location of 'La religieuse' is documented in the BGRF, where it goes back to the original string 'province'.
- We use controlled vocabularies to formulate standardized statements. Our vocabularies are built up step by step with concepts that are relevant to all three source types. They are also multilingual (FR, EN, DE). In the case of our thematic vocabulary, we have chosen a domain-specific resource as a starting point, the Dictionnaire européen des Lumières (Delon 1997). The spatial vocabulary was created by named entities found in the resources. The general approach for these and all other vocabularies in development is that we create the concepts as items and, if possible, match them to Wikidata items.
- As we consider MiMoTextBase a part of the Wikibase ecosystem, we have focused on mappings and matchings with Wikidata identifiers where possible. We intend to establish further links with the LOD cloud in the future (VIAF, BNF, GND etc.).
- For MiMoText, works and authors are the central classes, i.e. item types, in the Wikibase. We have so far focused on those statement types for which we can extract statements from at least two source types, because this enables comparability and goes hand in hand with relevance for the domain. In a first pilot project we concentrated on thematic statements, followed by spatial statements. The emphasis on the literary work implies that we partially reduce complexity (and thus increase interoperability and reusability) by also modeling the data from the bibliography exclusively on the work level and avoiding differentiations according to bibliographic standards (FRBR, SPAR ontologies). As with any reduction in complexity, you win some and you lose some, but for us the gain is more important.
- In order to increase comprehensibility and usability, we have structured the ontology in modules, see https://github.com/MiMoText/ontology
In total, there are now (May 30, 2023) 331671 triples in our graph.
You find information on 622 authors and on 1750 novels.
For example, for the literaray works, there are 1897 statements in the graph that connect to the property “narrative location” (P32).
Concerning the properties in our graph, this query gives you an overview:
There are properties and items with a
close match (P16) or an exact match (P13) on
Wikidata. To have a look at these matches between the MiMoText
knowledge graph and the Wikidata knowledge graph, we can query for
items with the corresponding property:
Query to items with a close match (P58) on Wikidata, dimensions view
Query to items with exact match (P30) on Wikidata, limited to 40 results, dimensions view
To access different information within a knowledge graph, you need to define the namespaces to define where to
find that information. The namespace is a URL pointing to the statement and looks like the following example:
<http://data.mimotext.uni-trier.de/entity/> These, of course, could be used within the
SPARQL query where-clause, but for a better readability, it is also possible to define prefixes for the
different namespaces used within a SPARQL query on the top of a query. In naming the prefixes, we followed the
Wikidata prefix convention, but turned them into MiMoTextBase specific prefixes.
Next to the prefixes for entities and properties, which are sufficient for most of the simple queries, there are many more for e.g. accessing statement nodes, where you can find references and quantifiers etc. As this can get quite complex, in this section we want to visualize different types of queries and the corresponding path in the data representation schema for the most relevant query types we use within the project that is: simple queries to access items at the object position and its label, statement nodes and the items within it, such as the label, the reference node including the reference itself and a corresponding quotation.
Please note: the example shown is a snippet of this entity
In our example the starting point is the item Q1053 that has the label "Les liasisons dangereuses" which is a
MiMoTextBase entity. It will be the subject for the following queries. Therefore the query will start with
mmd:Q1053 for referencing to this entity. Connected to it are different predicates and objects,
shown here is the predicate (property) "about" which has the ID P36. At the object position in our example
there is another entity having the label "libertinism" and the ID Q2969. Values at the object position can
themselves become a subject being connected to predicates and objects. This is called reification. In order to
access different levels of the statement group, we need to modify the prefixes used in the SPARQL queries.
The SPARQL data representation was created based on the SPARQL Wikidata data representation, for further information, please have a look here.
In the following you can click on one of the query types and you will see how to access the wanted information. Under the image you can find information about that query in more detail.
To retrieve simple values
and their labels such as Q1053 (is) about <topic> , you need the prefixes for
the entities and properties:
PREFIX mmd: <http://data.mimotext.uni-trier.de/entity/>
PREFIX mmdt: <http://data.mimotext.uni-trier.de/prop/direct/>
That means to get the (simple) value of the propery "about" (P36) we can use the direct path (within
the data representation) connecting the entity via mmdt (prop/direct) and assign a new variable at the
object position called "?topic". To this variable the value will be bound and returned in the result
table. You can execute the query in the SPARQL endpoint interface here.
The statement node in
this query is at the object position and can be retrieved using the prefix
PREFIX mmp: <http://data.mimotext.uni-trier.de/prop/>. It represents the whole node
and is connected to various different statements itself as you can see in the data representation.
Since we also want to get the statement connected to the property "about", we define the predicate as
mmp:P36
As this is the starting point for retrieving further information such as the references for a value,
it is shown separately here. Though if you run the query, you will notice that the result value is a
URL that only points to the statement internally.
You can try the query here. Please note: the result table will contain more statement nodes, one for each "about" statement.
In this query we want to illustrate the path to the simple value via the statement node. First we are
going to retrieve the statement node the same way as before:
mmdt:Q1053 mmp:P36 ?stmtNode. In the second part of the query the ?stmtNode itself
becomes the subject and is connected to the simple value via the property mmps which then
looks as follows: ?stmtNode mmps:P36 ?topic.
To retrieve the label of the topic you then could again either use the rdfs:label or the wikibase
label service.
You can try the query here. Please note: the result table will contain more topic items, that is all topic items connected to the item Q1053.
To query the reference value (and its label, e.g. "Schlüter_2014a"), you first have to acceess the statement node. In this example we further define the statement node using mmps:P36 mmd:Q2969 (="libertinism"). Using the statement node we can retrieve the reference node using prov:wasDerivedFrom and bind it to a new variable "?refNode". The reference node itself is connected with different properties, such as "stated in" (P18) and "quotation" (P42), both of which can be queried via the mmpr prefix.
To run the query in your browser, please click here
Linking with the Wikidata-Graph & prefixes
In the context of linking to the Wikidata cloud, we currently have several phases planned in the spirit of the 'Wikibase ecosystem', although we will probably not be able to realize all of them in the current project phase:
- mapping of thematic and spatial concepts in our controlled vocabularies (done).
- mapping of properties and classes (done)
- mapping of author and work items (in progress)
- creation of a MiMoText ID in Wikidata (future)
- linking the literary works we could map from Wikidata to the work items in our MiMoTextBase (future)
- Importing the work items not yet available in Wikidata into Wikidata and also linking them to our MiMoTextBase. (future) An interesting model project for this approach is the WeChangEd project.
The default setting for each Wikibase instance are the Wikidata prefixes. We will soon change these prefixes currently available in Wikibase, to avoid (among other) confusion in the context of 'federated queries'. We will stay within the Wikidata logic of the prefix labeling to increase usability for those who are already familiar with the Wikidata prefies (e.g. 'mmd' for the 'entities' with the prefix 'wd', 'mmdt' for the 'properties' with 'wdt').
Extensions of the MiMoTextBase & further modules
In the further course of the project until the end of 2023 (consolidation and evaluation phase), further statement types will be modeled step by step, for which there is data in at least two of our three source types. We also plan to LODify additional data from our central source that we have initially imported only as strings (e.g., distribution format, number of pages). Furthermore, we will increase interoperability with ELTeC and Wikidata by importing data on reusable properties ("language of work or name").
Furthermore, we plan to add the module "scholarly publication" and thus import data that have been manually annotated in INCEpTION so far, as well as automatically extracted statements (machine learning based on the annotated training data) in the future.
We would like to further increase the usability and accessibility of our MiMoTextBase, for example by importing the wordles for the respective topics.
For the future work concerning the MiMoText ontology, see: github.com/MiMoText/ontology
Further features, explanation and documentation
Multilinguality: Our vocabularies are already all trilingual (@en | @fr | @de). In the descriptions of our central Q-items and properties, we have currently limited these to English, but we do plan to make them trilingual as well.
Example queries: The Wikibase infrastructure offers the possibility to integrate sample queries directly in the SPARQLendpoint, with which users can explore the respective graph and at the same time have a kind of template of queries that can be adapted. We plan to provide this useful option soon.
Media files: To make our MiMoTextBase more illustrative, we will soon integrate image files. This concerns wordles of the topics, for example.
Documentation: We will gradually improve the documentation of the different resources and workflows in our project. Analyses with the MiMoTextBase The concrete value for research in literary studies and the humanities in general is very important in our view. We hope that researchers will be able to use the data for their studies, and at the same time we would like to examine the potentials of such data storage in our project by systematically exploring and statistically evaluating the relationships and interdepencies within the network (e.g. clustering, correlations).
MiMoTextBase data
For the provision of data as well as the infrastructure in the project, Open Science principles are fundamental. This concerns, among other things, the publication of FAIR data as well as the use of open source tools and software – in particular Wikibase.
All data of “Mining and Modeling Text” is made open as Public Domain (CC-0). Data can be reused for any purpose.
MiMoTextBase endpoint
| Description | Link | Data Type |
|---|---|---|
| SPARQL endpoint MiMoTextBase | https://query.mimotext.uni-trier.de/proxy/wdqs/bigdata/namespace/wdq/sparql | RDF |
If you want to cite our knowledge graph, please credit it with:
Citation suggestion
Maria Hinzmann, Anne Klee, Johanna Konstanciak, Julia Röttgermann,
Christof Schöch, Moritz Steffes: MiMoTextBase, Trier Center for
Digital Humanities, data.mimotext.uni-trier.de, 07/2022.
Reference paper
Schöch, Christof, Maria Hinzmann, Röttgermann Julia, Anne Klee, and
Katharina Dietz. “Smart Modelling for Literary History.” IJHAC:
International Journal of Humanities and Arts Computing [Special Issue
on Linked Open Data] 16, no. 1 (2022): 78–93. DOI:
https://doi.org/10.3366/ijhac.2022.0278
The full corpus of roman18
Our full corpus of french novels in full text is available on GitHub in plaintext and in XML/TEI. The plaintext version is normalized and modernized.
| Description | Link | Data Type |
|---|---|---|
| This folder contains the current corpus of French novels in full text 1751-1800 | https://github.com/MiMoText/roman18/tree/master/XML-TEI/files | XML/TEI |
| This folder contains the current corpus of French novels in plain text 1751-1800 | https://github.com/MiMoText/roman18/tree/master/plain/files | TXT |
| This list contains metadata on the full texts. | https://github.com/MiMoText/roman18/blob/master/XML-TEI/xml-tei_metadata.tsv | TSV |
Collection de romans français du dix-huitième siècle (1750-1800) / Eighteenth-Century French Novels (1750-1800), edited by Julia Röttgermann, with contributions from Julia Dudar, Anne Klee, Johanna Konstanciak, Amelie Probst, Sarah Rebecca Ondraszek and Christof Schöch. Release v0.2.0. Trier: TCDH, 2021. URL: https://github.com/mimotext/roman18 DOI: http://doi.org/10.5281/zenodo.5040855
MiMoText subset in European Literary text collection
A subset of 100 novels from the MiMoText corpus is published as an extension of the European Literary Text Collection (ELTeC).The corpus contains short, medium-length and long novels from this period. It includes epistolary novels, novels written in the first person, novels written in the third person as well as a small number of dialogical novels. The subset corpus includes 20 novels written by female authors.
| Description | Link | Data Type |
|---|---|---|
| Subset of 100 MiMoText novels in “European Literary Text Collection” | https://distantreading.github.io/ELTeC/fra-ext2/ | HTML |
| Metadata for the subset of 100 novels in “European Literary Text Collection” | https://github.com/COST-ELTeC/ELTeC-fra-ext2/blob/main/ELTeC-fra-ext2_metadata.tsv | TSV |
Further resources
MiMoTextBot
We use the Python library Pywikibot for inclusion of the RDF (Resource Description Framework) triples in our Wikibase instance. Pywikibot is a tool for automating work on a MediaWiki. For this process, we have developed an individual bot that allows us to easily import and update our data via TSV files. In order for this script to work, each TSV file has a self defined header. This header makes the import expandable. It is possible to add new properties, items and statements without further expenditure. The script can be found on our GitHub Repository Wikibase-Bot.
RDF Dump
Click to download.
Licence
All texts are in the public domain and can be reused without restrictions. We don’t claim any copyright or other rights on the transcription, markup or metadata. If you use our texts, for example in research or teaching, please reference this collection using the citation suggestion below.
Citation suggestion
Maria Hinzmann, Anne Klee, Johanna Konstanciak, Julia Röttgermann, Christof Schöch, Moritz Steffes: MiMoTextBase, Trier Center for Digital Humanities, 2022. URL: data.mimotext.uni-trier.de.