One major focus of the MiMoText graph are the authors who published novels in French during 1751-1800. Based on the Bibliographie du Genre Romanesque Français (Martin, Mylne, and Frautschi 1977), we extracted the authors of French novels whose first publication date lies in between that period, which means we excluded translations (in French) and re-editions.
The following query shows which authors are represented in the MiMoText graph via the property item occupation (P11) namely author (Q11):
Via changing the SELECT part to SELECT (count(?authorName) as ?count) you can get the total count of the authors represented in the graph: Query to retrieve the count of authors.
You can also get authors with the most publications of novels during 1751-1800 (top 20):
To get more information on the authors like dates of birth and death or people who influenced them, you can use federated queries to query Wikidata.
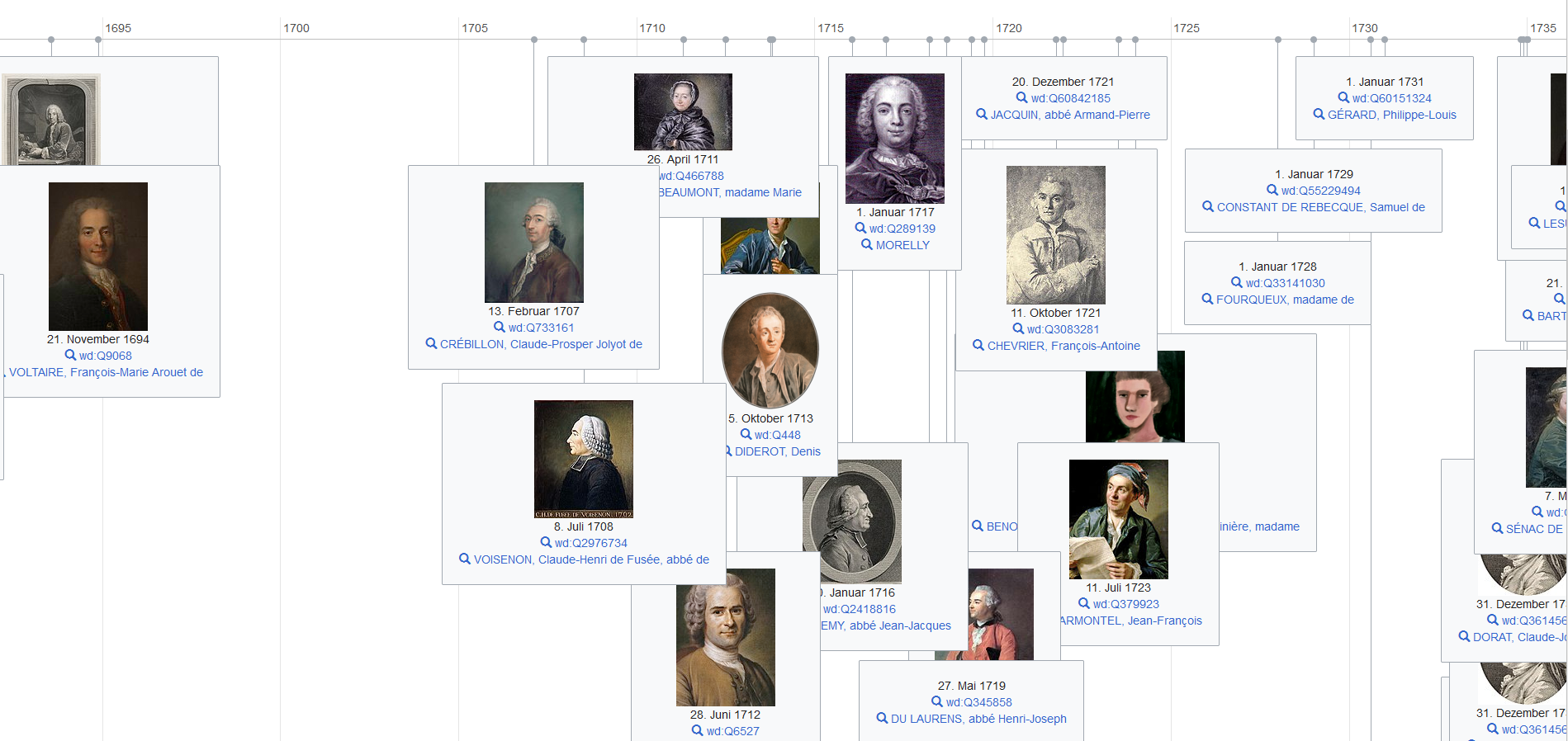
As described in the section above, federated queries allow querying several knowledge graphs at once. We can explore federated queries by querying the MiMoText graph and the Wikidata knowledge graph, making use of the Wikidata property date of birth and of the property image which allows us to see the date of birth of the authors in a timeline.
If you are new to SPARQL, you can go through the (short)Tutorial,which will give you an overview of how to write basic queries based on examples inMiMoTextBase. It’s supposed to give newbies an introduction to SPARQL, but it cannot give you a deep knowledge of SPARQL – maybe theseresourcescan help you with that.
If you are interested in MiMoTextBase and its content onauthors,novels,spacesorthemesof the French novel in 1751-1800 with already some SPARQL knowledge, you can have a look at the links.
WithinGOING FURTHER there are some queries on the data containing overviews of items like dates of publication or themes changing over time and comparing the different sources of the data inMiMoTextBase together with some interpretation on the outcome which could show the potential of initial questions on further research.
If you want more detailed information about the structure and the aims of our tutorial, you can find it in theintroduction of the tutorial.Information on the infrastructure and the models behind MiMoTextBase you can findhere.
Having no results in the result table can have different reasons. A simple solution is to check whether the variables are spelled the same in the SELECT and the WHERE part of the query.
Another reason could be being too specific in the query. Not all items in MiMoTextBase contain all information on all properties due to its sources. So it can be helpful to add the OPTIONAL function on some of the properties in your query, seehere.
The solution is easy: We have to aggregate ?authorName by grouping. We can now get the results in descending order via order by desc(?count) and set a limit of 20 to get the top 20.
Sometimes you can get many results on a query which can slow down the result generation or impair the readability of some visualizations. In those cases you could add the LIMIT-operation (seehere)to only get the TOP x items or the HAVING COUNT-operation (seehere)if you want only results that lie above a certain threshold.
If some of the items appear more often in the results than they should, make sure you filter all labels for one language (FR, EN, DE) separately as the graph is multilingual and the output will represent all languages within the graph, seehere.
If you're looking for the right identifier for properties, novels, authors, themes or locations, the simplest way is to visitdata.mimotext.uni-trier.deand type in the label (for example “London” or “about” or “philosophy”) in the search bar. The numerical identifier of the property or the item is visible in the URL or behind the name of the item or the property.
You can also consult our lists of themes, locations and properties and their numerical identifier in the knowledge graph below.
For a list of all thematic concepts in the graph, see thisquerywhich lists all thematic concepts and their Q-identifier, ordered by occurrence:
List of locations
For a list of all narrative places in the graph, see thisquerywhich lists all narrative places and their Q-Identifier, ordered by occurrence:
These queries list themes or locations ordered by occurrence. We recommend using items or properties which have a certain number of connections in the graph, in order to get good results (with enough data points).
There are several possible reasons for a slowdown or a timeout of your query. It could be that the quantity of results is very high, so you might limit the results to check if the syntax of the query is OK. This is done by using theLIMITparameter. The LIMIT tells the algorithm where to stop, so if you insert for example LIMIT 100 at the end of your query, it will stop after 100 results. This can be helpful for debugging.
Parameters which potentially slow down the query are DISTINCT or ORDER BY. A strategy might be to comment them out to see if these slow down your query.