Using SPARQL in Python
If you are interested in running SPARQL queries in python, here you can find some information on how to do so. One advantage in using a the wikibase and its query service is that it comes with different built-in code formats, such as HTML, JavaScript, R, python and more. Here you will find instructions in how to access those codes and how to use it further. The first steps will be explained here, the next steps will be shown in a jupyter notebook.
Step 1 - Write your query:
The first step is to write your SPARQL-Query within the SPARQL-Query endpoint interface, for example here in order to access the MiMoTextBase.
Example query In this tutorial we are using a quite simple query that is listing all literary works and their year of publication within the MiMoTextBase. You can find the query here
Step 2 - Run query:
Run your query! This step is necessary to display the “Code”-Option where you can find the different code embeddings of the query.
Step 3 - Access code:
Once the result generation is finished, you will find some additional options in the interface in between the query field and the result.
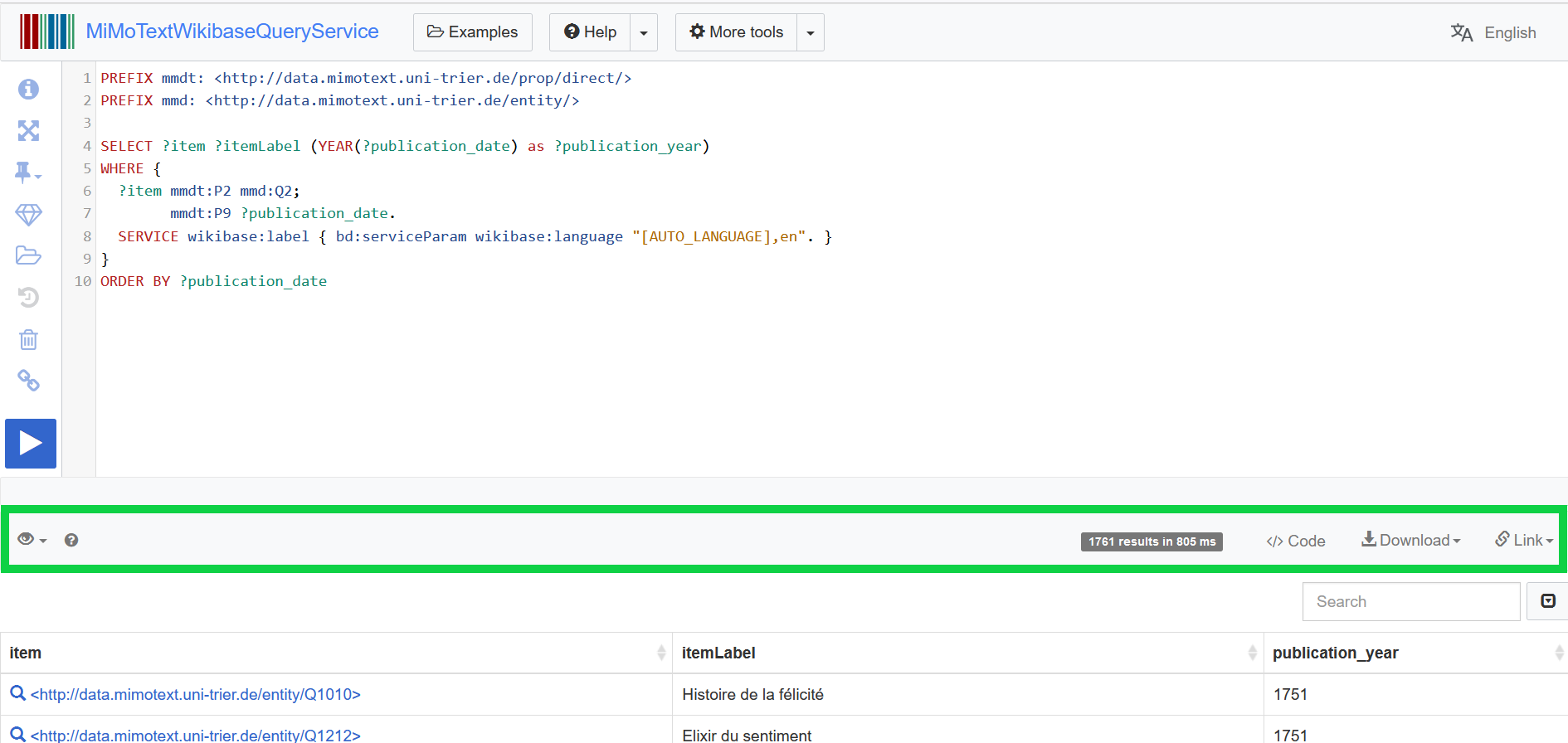
If you click on the </>Code-Button, a new window will open showing all options for embedding the recently run query in different coding languages.
Now you can choose python and you will get the code that is necessary to run the query within a python script.
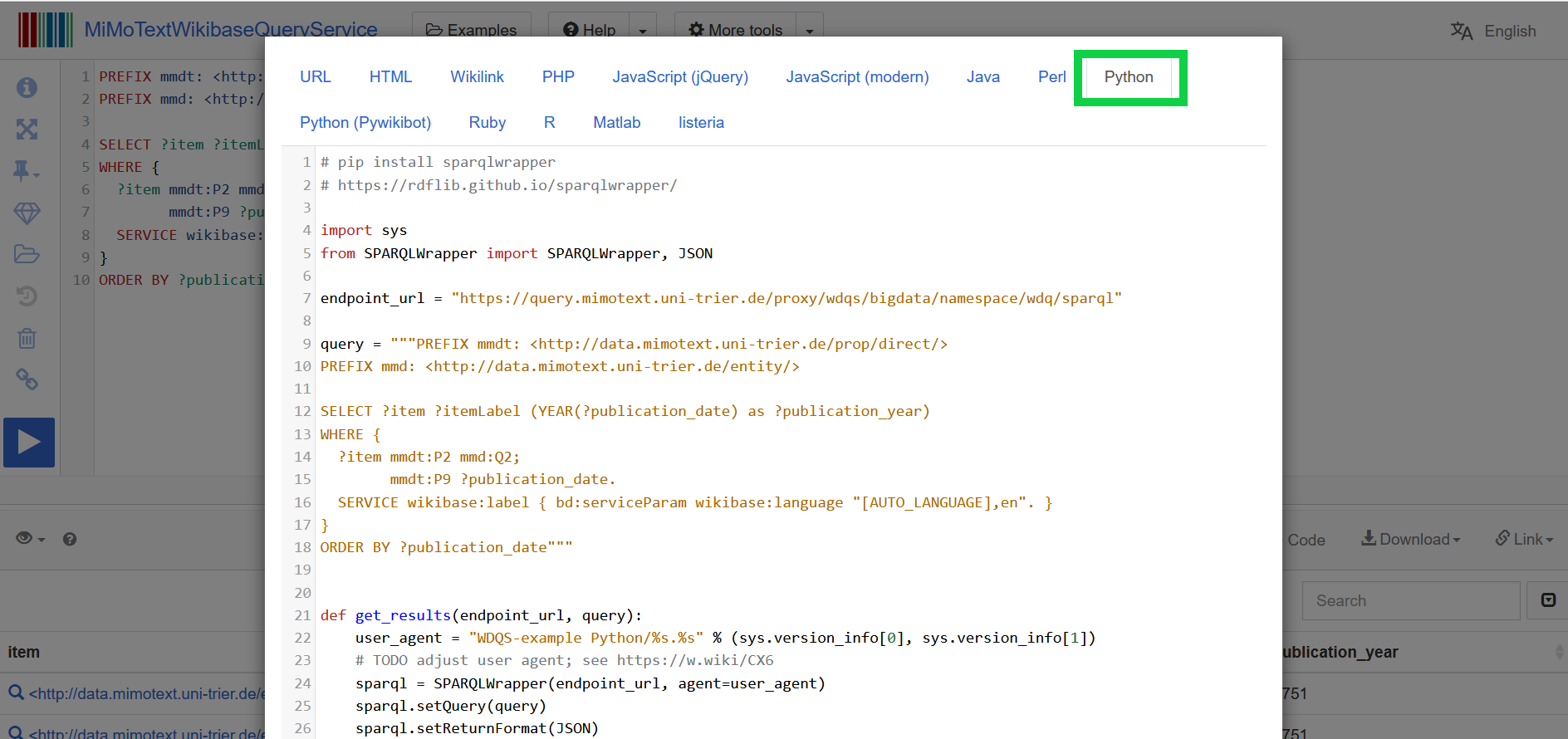
Step 4 - Install libraries:
Here you can also see all python libraries that are used for running the query, that is sys and SPARQLWrapper - the latter you may have to install if you are using it for the first time. For more information on how to do so, see the documentation.
Step 5 - Copy and paste code:
Now you are ready to copy the generated code into your python script. For this and the next steps, you can find our example in a jupyter notebook here:
![]()
Binder in main
![]()